概要
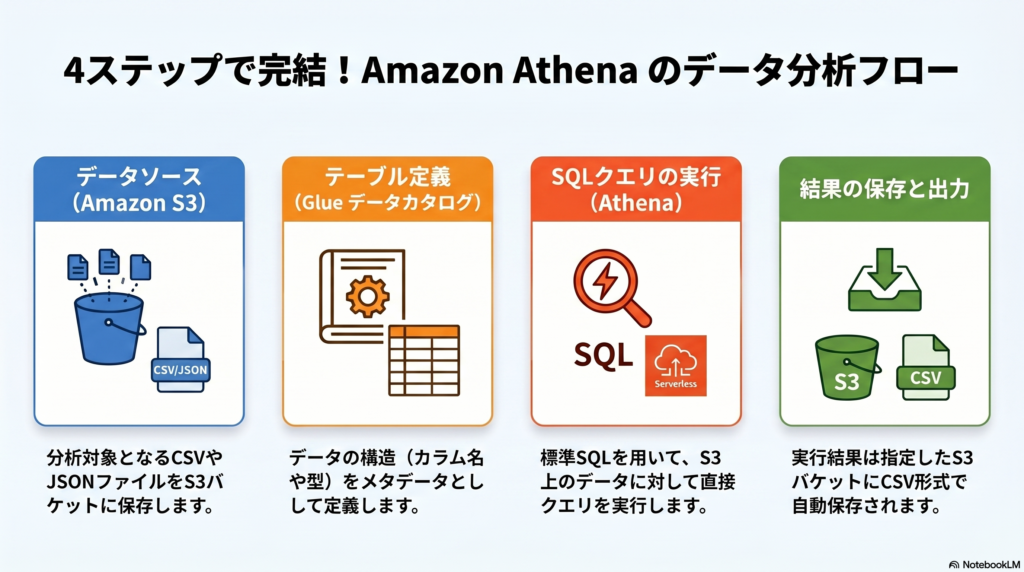
Amazon Athena は、Amazon S3 に保存されたデータを標準的な SQL を使って直接分析できるサーバーレスのクエリサービスです。データベースサーバーの構築やデータのロードといった準備作業が不要で、S3 上のデータに対してすぐにクエリを実行できます。
ログ分析、データ探索、レポート作成など、さまざまなユースケースで活用されています。特に CloudTrail ログや ALB アクセスログなど、S3 に蓄積される AWS サービスのログを分析する場面で頻繁に使用されます。
本記事では、S3 にサンプルデータを配置し、Athena でテーブルを定義してクエリを実行するまでの一連の流れを体験します。
この記事のメリット
- Amazon Athena の基本的な仕組みとユースケースを理解できる
- S3 上のデータに対してテーブルを定義し、SQL クエリで分析する手順を習得できる
- Athena のデータベース・テーブル・クエリ結果の保存先といった基本概念を把握できる
- サーバーレスでのデータ分析の利便性を体験できる
キャラクター紹介
クラウド資格実践ラボの基礎学習記事では、ルクシーちゃんと代表の土肥が対話形式で AWS 認定試験で必要な知識をハンズオンとともに解説していくブログです。これからこのブログを案内する2人を紹介します。

ルクシーちゃん
クラウド資格に挑戦中の好奇心旺盛なナビゲーター。初学者目線で「これってなんだろう?」と素朴な疑問を投げかけ、知識を引き出していく役どころ。難しい内容も、ルクシーちゃんと一緒なら一歩ずつ理解できると思います!
土肥(とひ)
株式会社Luxyの代表であり同社の元エンジニア。これまでオンプレとAWS環境のインフラを担当。AWS認定資格の学習で得た知識をハンズオンとともに解説するのが得意。直近では新人の教育なども行っており、これから技術を学ぼうという方が納得できるように解説できることに喜びを感じているとのこと。
技術解説
Amazon Athena とは
 Luxyちゃん
Luxyちゃんとひさん、Amazon Athena ってどんなサービスなんですか?
Athena は、S3 に保存されたデータに対して SQL クエリを実行できるサービスだよ。中身は Apache Presto がベースになっていて、標準 SQL(ANSI SQL)が使えるんだ。
LuxyちゃんSQL が使えるんですね!でもデータベースサーバーとか用意しなくていいんですか?
そこが Athena のいいところで、サーバーレスなんだ。インフラの管理は一切不要。S3 にデータを置いておけば、すぐに SQL で分析できるよ。
Luxyちゃんお金はどのくらいかかるんですか?
クエリがスキャンしたデータ量に対してだけ課金される仕組みだよ。使わなければお金はかからないし、1TB あたり 5 USD っていうシンプルな料金体系なんだ。
主な特徴
LuxyちゃんAthena の特徴をもう少し教えてください!
まとめるとこんな感じだよ。
- サーバーレス: サーバーのプロビジョニングや管理が不要
- 標準 SQL 対応: 使い慣れた SQL 構文でクエリを記述可能
- 多様なデータ形式に対応: CSV、JSON、Parquet、ORC、Avro など
- S3 との統合: S3 上のデータをそのまま分析でき、データの移動やロードが不要
- スキャン量課金: クエリがスキャンしたデータ量に対して課金(1TB あたり 5 USD)
 Luxyちゃん
LuxyちゃんCSV とか JSON とかいろんな形式に対応してるんですね。データを別の場所にコピーしなくていいのは楽ですね!
そうそう。たとえば CloudTrail のログとか ALB のアクセスログって、もともと S3 に保存されるでしょ?それをそのまま Athena で分析できるから、ログ調査にすごく便利なんだ。
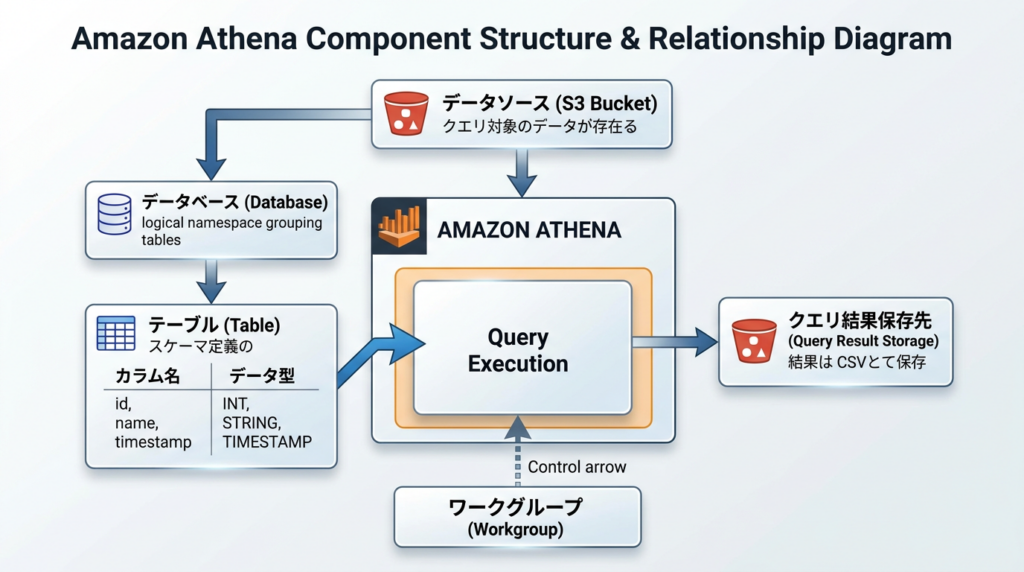
基本的な構成要素
LuxyちゃんAthena を使うときに知っておくべき要素ってありますか?
いい質問だね!Athena にはいくつかの構成要素があるから、整理しておこう。
| 要素 | 説明 |
|---|---|
| データソース | クエリ対象のデータが格納されている場所(S3 バケット) |
| データベース | テーブルをグループ化する論理的な名前空間 |
| テーブル | データのスキーマ(カラム名、データ型)を定義したメタデータ |
| クエリ結果の保存先 | クエリ結果が CSV 形式で出力される S3 バケット |
| ワークグループ | クエリの実行環境を管理する単位(アクセス制御やコスト管理に使用) |
 Luxyちゃん
Luxyちゃんテーブルは「メタデータ」なんですね。データそのものじゃなくて?
そう、いいところに気づいたね!Athena のテーブルはデータの「定義」だけを持っていて、実際のデータは S3 に置いたままなんだ。だから「外部テーブル(EXTERNAL TABLE)」って呼ばれるよ。
データカタログと AWS Glue
Luxyちゃんテーブルの定義ってどこに保存されるんですか?
Athena はデフォルトで AWS Glue データカタログをメタデータストアとして使うんだ。作成したデータベースやテーブルの定義は全部 Glue データカタログに保存されるよ。
LuxyちゃんGlue って名前は聞いたことあります。テーブルを自動で作ってくれる機能もあるんですか?
Glue クローラーっていう機能を使うと、S3 上のデータを自動スキャンしてスキーマを検出し、テーブルを自動作成できるよ。ただ今回のハンズオンでは、Athena のクエリエディタから CREATE TABLE 文を直接書いてテーブルを定義する方法でやっていくね。まずは基本を押さえよう!
実践
前提条件
- リージョン:
ap-northeast-1(東京) - S3 バケットを作成できる IAM 権限があること
- Athena を操作できる IAM 権限があること
作成するリソース一覧
| リソース種別 | リソース名 | 用途 |
|---|---|---|
| S3 バケット | athena-handson-data-<アカウントID>-ap-norheast-1-an | サンプルデータの格納先 |
| S3 バケット | athena-handson-results-<アカウントID>-ap-northeast-1--an | クエリ結果の保存先 |
| Athena データベース | handson_db | テーブルを格納するデータベース |
| Athena テーブル | sales_data | サンプルデータのスキーマ定義 |
S3 バケット名はグローバルで一意にする必要があるため、
<アカウントID>の部分をご自身の AWS アカウント ID に置き換えてください。
ステップ1: サンプルデータの準備と S3 へのアップロード
まず、分析対象のサンプルデータを作成し、S3 にアップロードします。
ローカルマシンで以下の内容のファイルを sales_data.csv として保存します。
$ cat sales_data.csv
order_id,product_name,category,quantity,unit_price,order_date
1001,ノートPC,Electronics,2,89000,2024-01-15
1002,マウス,Electronics,5,3500,2024-01-16
1003,デスク,Furniture,1,45000,2024-01-17
1004,チェア,Furniture,3,28000,2024-01-18
1005,モニター,Electronics,2,52000,2024-01-20
1006,キーボード,Electronics,10,8000,2024-01-22
1007,本棚,Furniture,1,35000,2024-01-25
1008,ヘッドセット,Electronics,4,12000,2024-02-01
1009,デスクライト,Furniture,2,6500,2024-02-03
1010,USBハブ,Electronics,8,2500,2024-02-05ステップ2: データ格納用 S3 バケットの作成とアップロード
- AWS マネジメントコンソールにログインし、リージョンが
ap-northeast-1(東京)であることを確認します - 上部の検索バーに
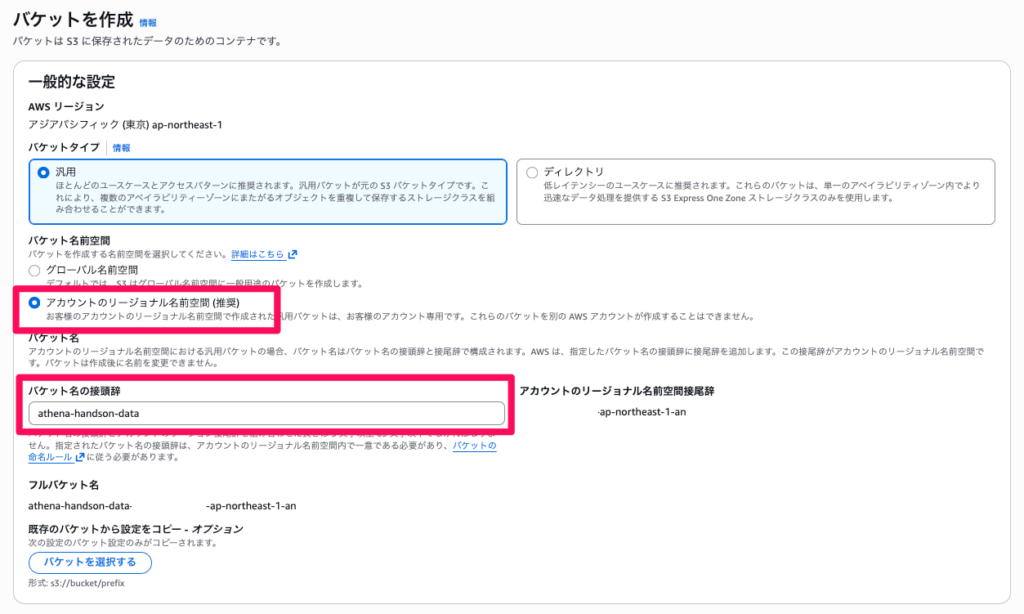
S3と入力し、表示された「S3」を選択します - 「バケットを作成」をクリックします
- 「アカウントリージョナル名前空間(推奨)」にチェックを入れます
- バケット名に
athena-handson-dataと入力します - リージョンが「アジアパシフィック(東京)ap-northeast-1」であることを確認します
- その他の項目はデフォルトのままにします
- 「バケットを作成」をクリックします
- 作成されたバケットをクリックして開きます
- 「フォルダの作成」をクリックし、フォルダ名に
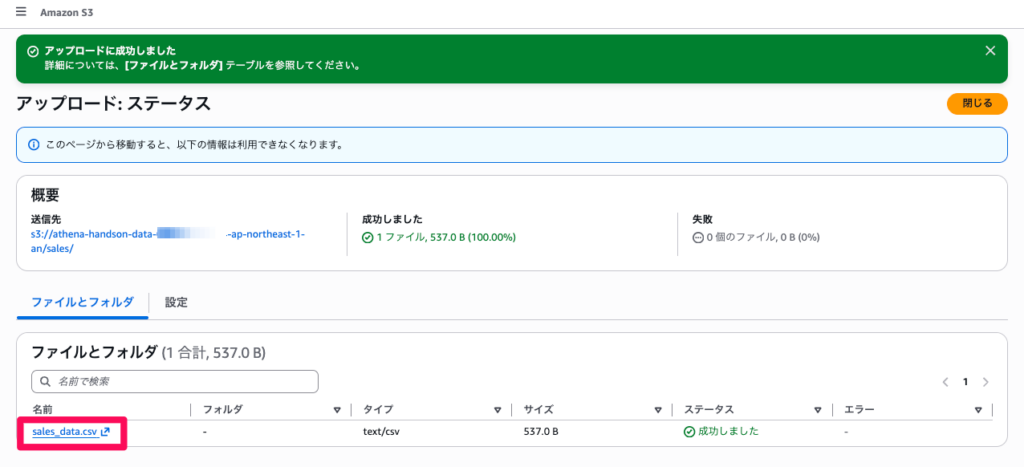
salesと入力して「フォルダの作成」をクリックします salesフォルダを開き、「アップロード」をクリックします- 「ファイルを追加」をクリックし、先ほど作成した
sales_data.csvを選択します - 「アップロード」をクリックします
ステップ3: クエリ結果保存用 S3 バケットの作成
- S3 コンソールのトップに戻り、「バケットを作成」をクリックします
- 「アカウントリージョナル名前空間(推奨)」にチェックを入れます
- バケット名に
athena-handson-resultsと入力します - リージョンが「アジアパシフィック(東京)ap-northeast-1」であることを確認します
- その他の項目はデフォルトのままにします
- 「バケットを作成」をクリックします
ステップ4: Athena のクエリ結果保存先を設定する
- 上部の検索バーに
Athenaと入力し、表示された「Athena」を選択します - 「クエリエディタ」をクリックします
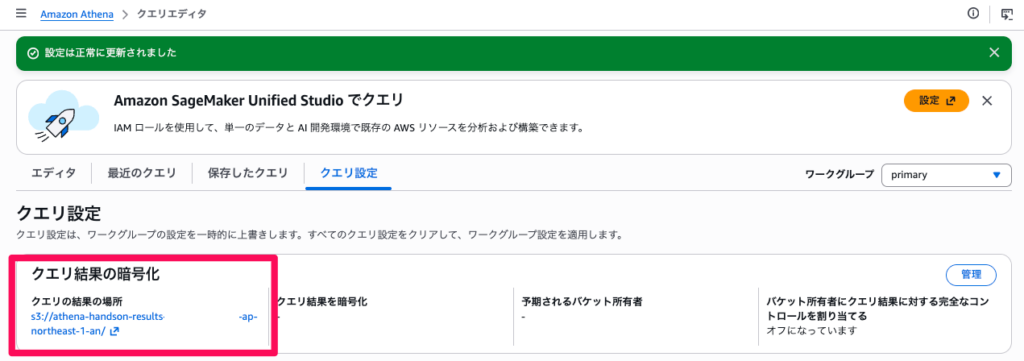
- 上部に「クエリを実行する前に、クエリ結果の場所を Amazon S3 に設定する必要があります」というメッセージが表示されている場合は、「設定を編集」をクリックします。表示されていない場合は、上部タブの「設定」を選択し、「管理」をクリックします
- 「クエリ結果の場所」に 先程作成した結果保存用のバケットを指定します
- 「保存」をクリックします
ステップ5: データベースの作成
- 「エディタ」タブを選択します
- クエリエディタに以下の SQL を入力します
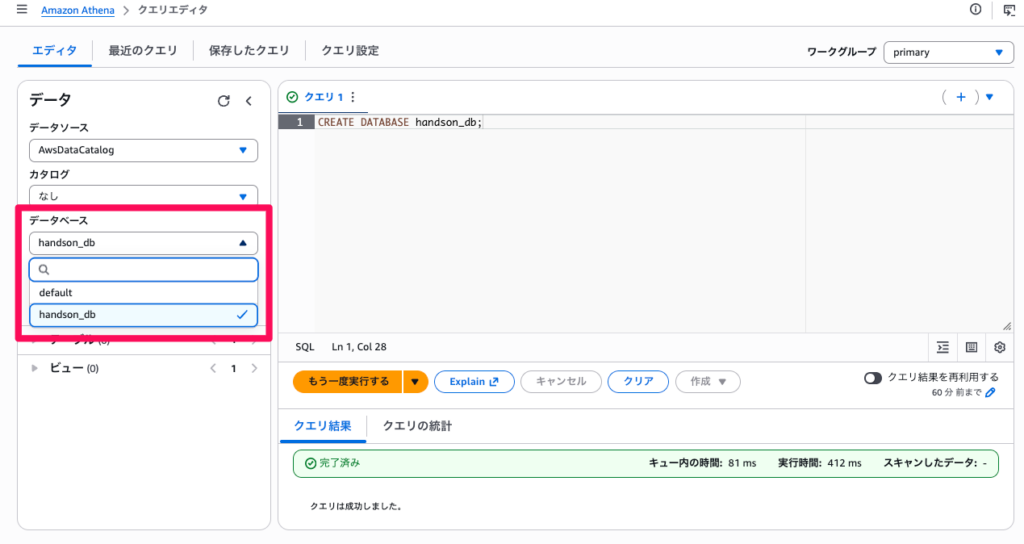
CREATE DATABASE handson_db;- 「実行」をクリックします
- 「クエリは成功しました」と表示されることを確認します
- 左側パネルの「データベース」ドロップダウンから
handson_dbを選択します
ステップ6: テーブルの作成
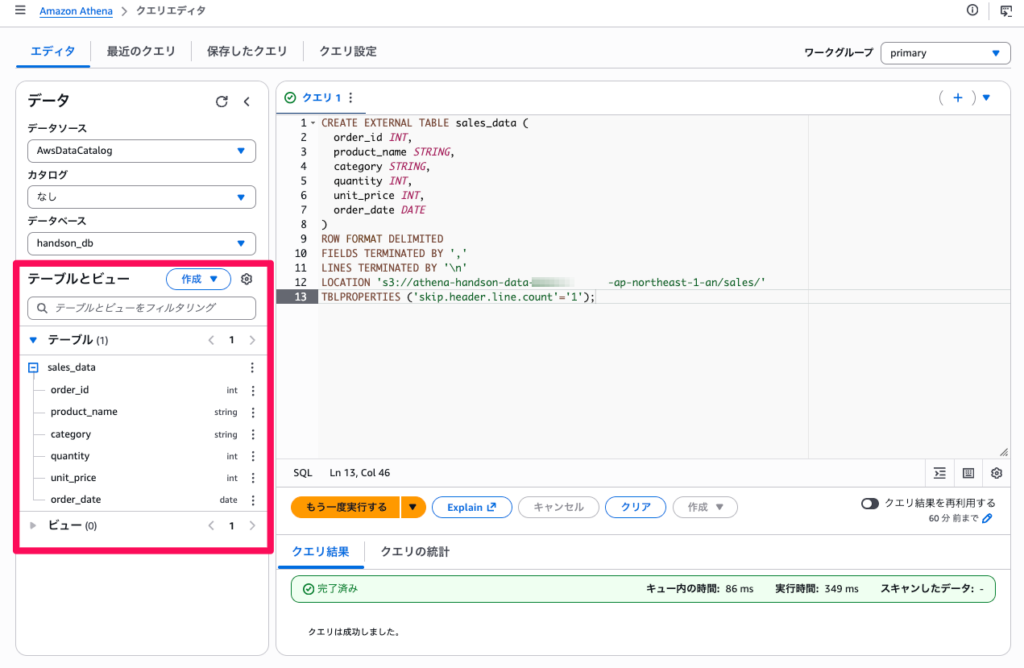
- クエリエディタに以下の SQL を入力します
CREATE EXTERNAL TABLE sales_data (
order_id INT,
product_name STRING,
category STRING,
quantity INT,
unit_price INT,
order_date DATE
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
LOCATION 's3://athena-handson-data-<アカウントID>-ap-northeast-1-an/sales/'
TBLPROPERTIES ('skip.header.line.count'='1');
<アカウントID>をご自身のアカウント ID に置き換えてください。skip.header.line.countプロパティにより、CSV のヘッダー行がスキップされます。
- 「実行」をクリックします
- 「クエリは成功しました」と表示されることを確認します
- 左側パネルの「テーブル」に
sales_dataが表示されます
ステップ7: データの確認クエリを実行する
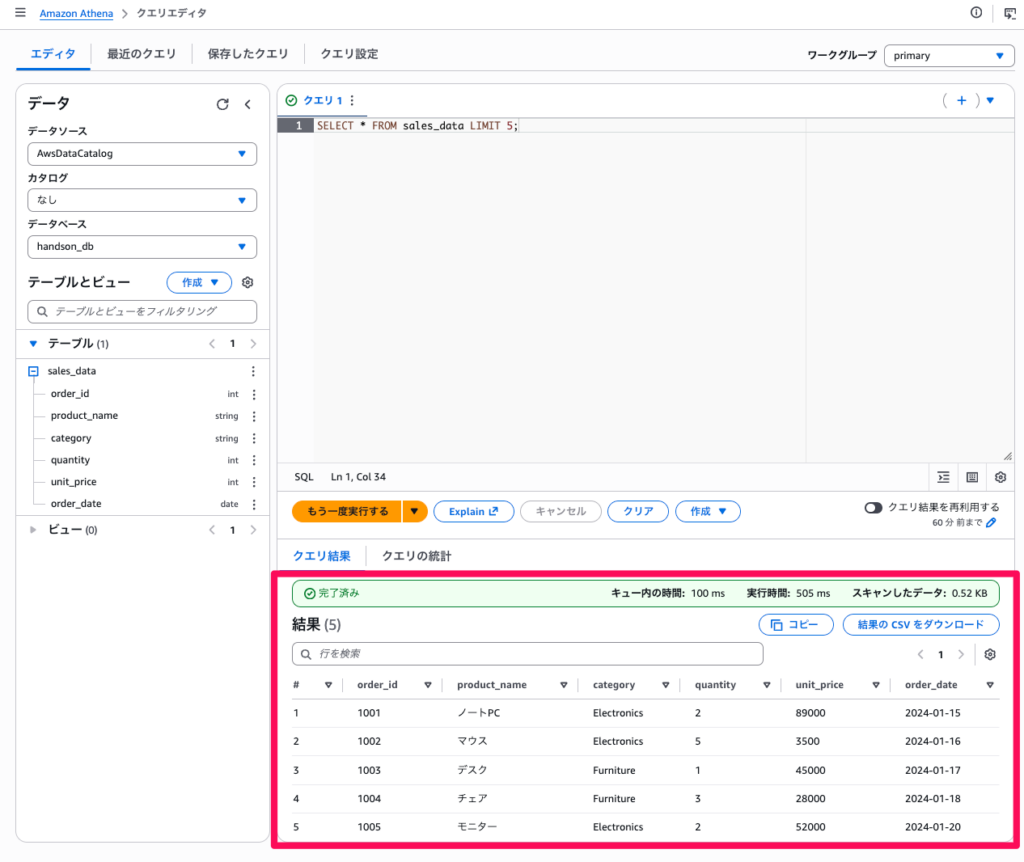
テーブルに対してクエリを実行し、データを確認します。
- クエリエディタに以下の SQL を入力し、「実行」をクリックします
SELECT * FROM sales_data LIMIT 5;- 結果タブにデータが表示されることを確認します
ステップ8: 集計クエリを実行する
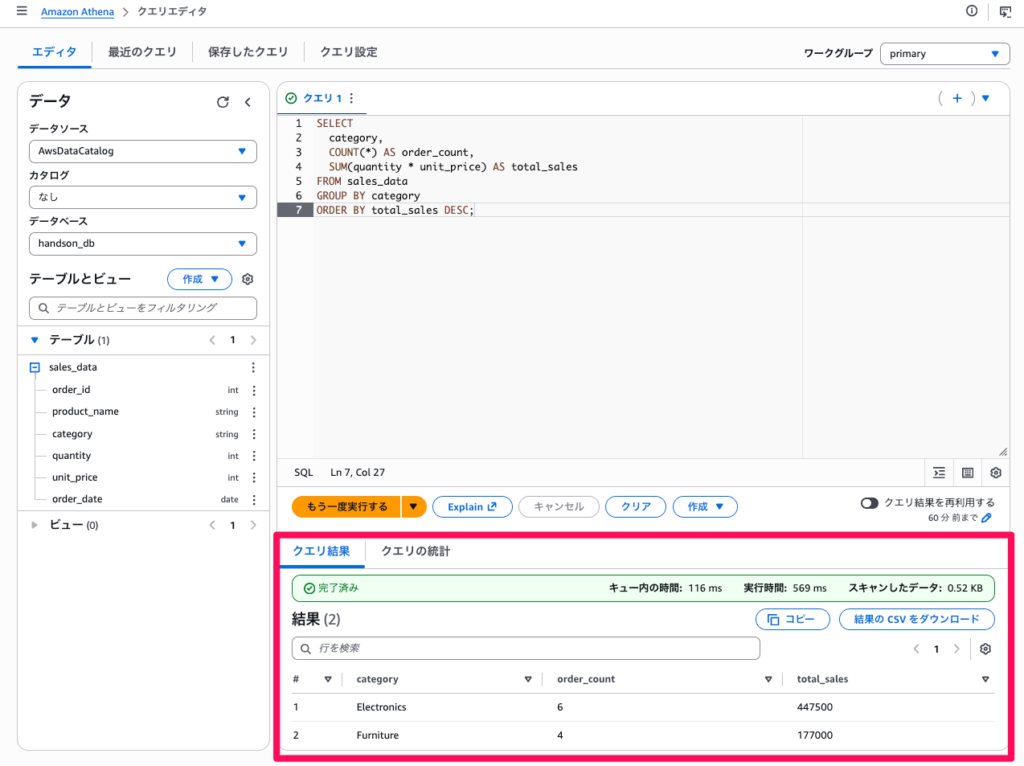
カテゴリごとの売上合計を集計してみます。
- クエリエディタに以下の SQL を入力し、「実行」をクリックします
SELECT
category,
COUNT(*) AS order_count,
SUM(quantity * unit_price) AS total_sales
FROM sales_data
GROUP BY category
ORDER BY total_sales DESC;- 結果タブにカテゴリ別の注文件数と売上合計が表示されます
ステップ9: 条件付きクエリを実行する
特定の条件でデータを絞り込んでみます。
- クエリエディタに以下の SQL を入力し、「実行」をクリックします
SELECT
order_id,
product_name,
quantity,
unit_price,
quantity * unit_price AS total_amount
FROM sales_data
WHERE category = 'Electronics'
AND quantity * unit_price >= 20000
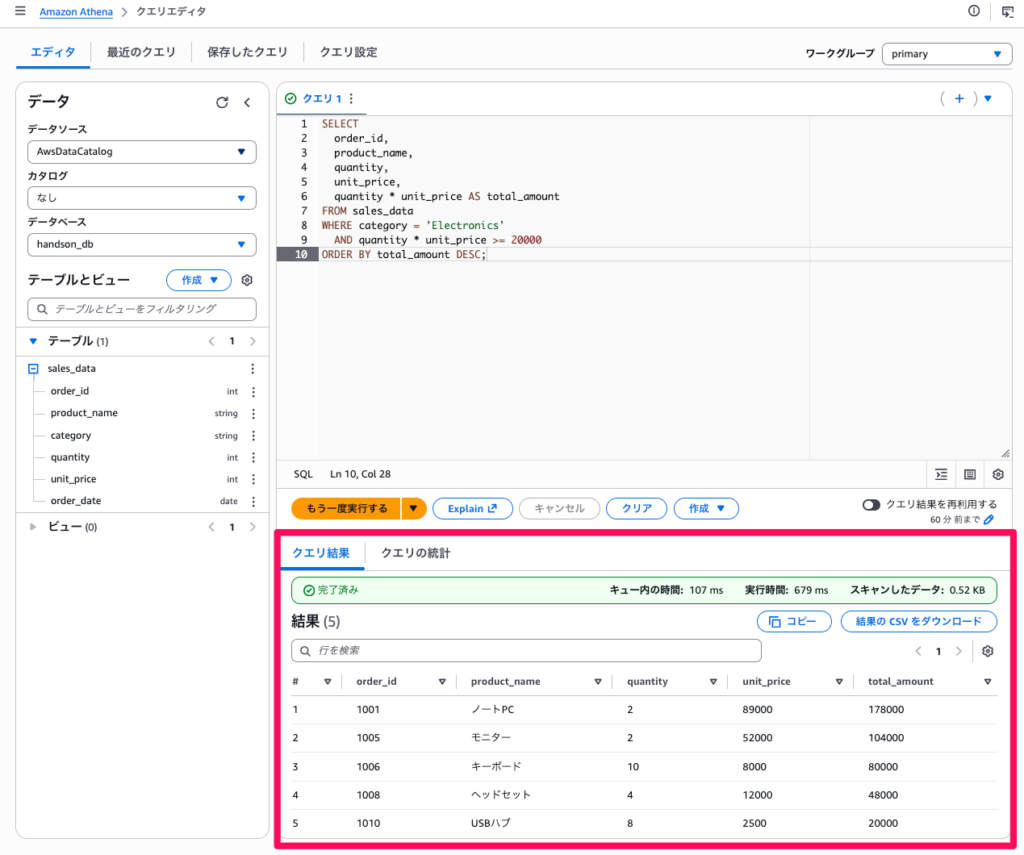
ORDER BY total_amount DESC;- Electronics カテゴリで合計金額が 20,000 円以上の注文が表示されます
まとめ
- Amazon Athena は S3 上のデータに対して SQL クエリを実行できるサーバーレスのクエリサービスです
- サーバーの構築やデータのロードが不要で、S3 にデータを配置するだけですぐに分析を開始できます
CREATE DATABASEでデータベースを作成し、CREATE EXTERNAL TABLEでテーブルのスキーマと S3 上のデータの場所を定義します- 標準 SQL(SELECT、WHERE、GROUP BY、ORDER BY など)を使って柔軟にデータを分析できます
- クエリ結果は指定した S3 バケットに CSV 形式で自動保存されます
- CloudTrail ログや ALB ログなど、S3 に蓄積される各種ログの分析に広く活用されています